PIMMS Tutorial: Scikit-learn style transformers#
Load data into pandas dataframe
Fit model on training data, potentially specify validation data
Impute only missing values with predictions from model
Autoencoders need wide training data, i.e. a sample with all its features’ intensities, whereas Collaborative Filtering needs long training data, i.e. sample identifier a feature identifier and the intensity. Both data formats can be transformed into each other, but models using long data format do not need to take care of missing values.
import os
from importlib import metadata
IN_COLAB = 'COLAB_GPU' in os.environ
if IN_COLAB:
try:
_v = metadata.version('pimms-learn')
print(f"Running in colab and pimms-learn ({_v}) is installed.")
except metadata.PackageNotFoundError:
print("Install PIMMS...")
# !pip install git+https://github.com/RasmussenLab/pimms.git
!pip install pimms-learn
If on colab, please restart the environment and run everything from here on.
Specify example data:
import os
IN_COLAB = 'COLAB_GPU' in os.environ
fn_intensities = 'data/dev_datasets/HeLa_6070/protein_groups_wide_N50.csv'
if IN_COLAB:
fn_intensities = ('https://raw.githubusercontent.com/RasmussenLab/pimms/main/'
'project/data/dev_datasets/HeLa_6070/protein_groups_wide_N50.csv')
Load package.
Parameters#
Can be set by papermill on the command line or manually in the (colab) notebook.
fn_intensities: str = fn_intensities # path or url to the data file in csv format
index_name: str = 'Sample ID' # name of the index column
column_name: str = 'protein group' # name of the column index
select_features: bool = True # Whether to select features based on prevalence
feat_prevalence: float = 0.2 # minimum prevalence of a feature to be included
sample_completeness: float = 0.3 # minimum completeness of a sample to be included
sample_splits: bool = True # Whether to sample validation and test data
frac_non_train: float = 0.1 # fraction of non training data (validation and test split)
frac_mnar: float = 0.0 # fraction of missing not at random data, rest: missing completely at random
random_state: int = 42 # random state for reproducibility
Data#
| AAAS | AACS | AAMDC | AAMP | AAR2 | AARS | AARS2 | AASDHPPT | AATF | ABCB10 | ... | ZNHIT2 | ZNRF2 | ZPR1 | ZRANB2 | ZW10 | ZWILCH | ZWINT | ZYX | hCG_2014768;TMA7 | pk;ZAK | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| 2019_12_18_14_35_Q-Exactive-HF-X-Orbitrap_6070 | 341,970,000.000 | 73,598,000.000 | NaN | 114,990,000.000 | 159,370,000.000 | 4,916,300,000.000 | 149,190,000.000 | 245,660,000.000 | 407,590,000.000 | 72,440,000.000 | ... | 50,194,000.000 | 23,201,000.000 | 332,480,000.000 | 477,690,000.000 | 484,070,000.000 | NaN | 21,823,000.000 | 721,850,000.000 | 283,680,000.000 | 7,714,600.000 |
| 2019_12_19_19_48_Q-Exactive-HF-X-Orbitrap_6070 | 211,690,000.000 | 33,991,000.000 | 19,762,000.000 | 80,960,000.000 | 155,320,000.000 | 4,233,400,000.000 | 96,914,000.000 | 306,530,000.000 | 257,840,000.000 | 55,844,000.000 | ... | NaN | NaN | 294,320,000.000 | 161,550,000.000 | 317,600,000.000 | NaN | NaN | 283,840,000.000 | NaN | NaN |
| 2019_12_20_14_15_Q-Exactive-HF-X-Orbitrap_6070 | 342,650,000.000 | 14,015,000.000 | NaN | 143,640,000.000 | 174,350,000.000 | 7,929,200,000.000 | 191,730,000.000 | 373,270,000.000 | 458,030,000.000 | 115,780,000.000 | ... | 38,113,000.000 | NaN | 525,090,000.000 | 167,830,000.000 | 702,420,000.000 | NaN | 58,540,000.000 | 772,560,000.000 | NaN | NaN |
| 2019_12_27_12_29_Q-Exactive-HF-X-Orbitrap_6070 | 118,930,000.000 | NaN | NaN | 80,158,000.000 | NaN | 4,081,400,000.000 | 74,818,000.000 | 208,420,000.000 | 242,070,000.000 | 42,650,000.000 | ... | NaN | 12,589,000.000 | 208,620,000.000 | 162,760,000.000 | 282,950,000.000 | NaN | 27,023,000.000 | 461,970,000.000 | NaN | NaN |
| 2019_12_29_15_06_Q-Exactive-HF-X-Orbitrap_6070 | 177,550,000.000 | 129,510,000.000 | 15,272,000.000 | 132,520,000.000 | 96,217,000.000 | 3,854,300,000.000 | 42,534,000.000 | 179,130,000.000 | 186,440,000.000 | NaN | ... | 25,275,000.000 | NaN | 59,980,000.000 | 673,000,000.000 | 188,690,000.000 | 88,943,000.000 | NaN | 1,438,800,000.000 | NaN | 128,670,000.000 |
5 rows × 4535 columns
We will need the data in long format for Collaborative Filtering. Naming both the row and column index assures that the data can be transformed very easily into long format:
| protein group | AAAS | AACS | AAMDC | AAMP | AAR2 | AARS | AARS2 | AASDHPPT | AATF | ABCB10 | ... | ZNHIT2 | ZNRF2 | ZPR1 | ZRANB2 | ZW10 | ZWILCH | ZWINT | ZYX | hCG_2014768;TMA7 | pk;ZAK |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| 2019_12_18_14_35_Q-Exactive-HF-X-Orbitrap_6070 | 341,970,000.000 | 73,598,000.000 | NaN | 114,990,000.000 | 159,370,000.000 | 4,916,300,000.000 | 149,190,000.000 | 245,660,000.000 | 407,590,000.000 | 72,440,000.000 | ... | 50,194,000.000 | 23,201,000.000 | 332,480,000.000 | 477,690,000.000 | 484,070,000.000 | NaN | 21,823,000.000 | 721,850,000.000 | 283,680,000.000 | 7,714,600.000 |
| 2019_12_19_19_48_Q-Exactive-HF-X-Orbitrap_6070 | 211,690,000.000 | 33,991,000.000 | 19,762,000.000 | 80,960,000.000 | 155,320,000.000 | 4,233,400,000.000 | 96,914,000.000 | 306,530,000.000 | 257,840,000.000 | 55,844,000.000 | ... | NaN | NaN | 294,320,000.000 | 161,550,000.000 | 317,600,000.000 | NaN | NaN | 283,840,000.000 | NaN | NaN |
| 2019_12_20_14_15_Q-Exactive-HF-X-Orbitrap_6070 | 342,650,000.000 | 14,015,000.000 | NaN | 143,640,000.000 | 174,350,000.000 | 7,929,200,000.000 | 191,730,000.000 | 373,270,000.000 | 458,030,000.000 | 115,780,000.000 | ... | 38,113,000.000 | NaN | 525,090,000.000 | 167,830,000.000 | 702,420,000.000 | NaN | 58,540,000.000 | 772,560,000.000 | NaN | NaN |
| 2019_12_27_12_29_Q-Exactive-HF-X-Orbitrap_6070 | 118,930,000.000 | NaN | NaN | 80,158,000.000 | NaN | 4,081,400,000.000 | 74,818,000.000 | 208,420,000.000 | 242,070,000.000 | 42,650,000.000 | ... | NaN | 12,589,000.000 | 208,620,000.000 | 162,760,000.000 | 282,950,000.000 | NaN | 27,023,000.000 | 461,970,000.000 | NaN | NaN |
| 2019_12_29_15_06_Q-Exactive-HF-X-Orbitrap_6070 | 177,550,000.000 | 129,510,000.000 | 15,272,000.000 | 132,520,000.000 | 96,217,000.000 | 3,854,300,000.000 | 42,534,000.000 | 179,130,000.000 | 186,440,000.000 | NaN | ... | 25,275,000.000 | NaN | 59,980,000.000 | 673,000,000.000 | 188,690,000.000 | 88,943,000.000 | NaN | 1,438,800,000.000 | NaN | 128,670,000.000 |
5 rows × 4535 columns
Data transformation: log2 transformation#
Transform the data using the logarithm, here using base 2:
| protein group | AAAS | AACS | AAMDC | AAMP | AAR2 | AARS | AARS2 | AASDHPPT | AATF | ABCB10 | ... | ZNHIT2 | ZNRF2 | ZPR1 | ZRANB2 | ZW10 | ZWILCH | ZWINT | ZYX | hCG_2014768;TMA7 | pk;ZAK |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| 2019_12_18_14_35_Q-Exactive-HF-X-Orbitrap_6070 | 28.349 | 26.133 | NaN | 26.777 | 27.248 | 32.195 | 27.153 | 27.872 | 28.603 | 26.110 | ... | 25.581 | 24.468 | 28.309 | 28.831 | 28.851 | NaN | 24.379 | 29.427 | 28.080 | 22.879 |
| 2019_12_19_19_48_Q-Exactive-HF-X-Orbitrap_6070 | 27.657 | 25.019 | 24.236 | 26.271 | 27.211 | 31.979 | 26.530 | 28.191 | 27.942 | 25.735 | ... | NaN | NaN | 28.133 | 27.267 | 28.243 | NaN | NaN | 28.081 | NaN | NaN |
| 2019_12_20_14_15_Q-Exactive-HF-X-Orbitrap_6070 | 28.352 | 23.740 | NaN | 27.098 | 27.377 | 32.885 | 27.515 | 28.476 | 28.771 | 26.787 | ... | 25.184 | NaN | 28.968 | 27.322 | 29.388 | NaN | 25.803 | 29.525 | NaN | NaN |
| 2019_12_27_12_29_Q-Exactive-HF-X-Orbitrap_6070 | 26.826 | NaN | NaN | 26.256 | NaN | 31.926 | 26.157 | 27.635 | 27.851 | 25.346 | ... | NaN | 23.586 | 27.636 | 27.278 | 28.076 | NaN | 24.688 | 28.783 | NaN | NaN |
| 2019_12_29_15_06_Q-Exactive-HF-X-Orbitrap_6070 | 27.404 | 26.948 | 23.864 | 26.982 | 26.520 | 31.844 | 25.342 | 27.416 | 27.474 | NaN | ... | 24.591 | NaN | 25.838 | 29.326 | 27.491 | 26.406 | NaN | 30.422 | NaN | 26.939 |
5 rows × 4535 columns
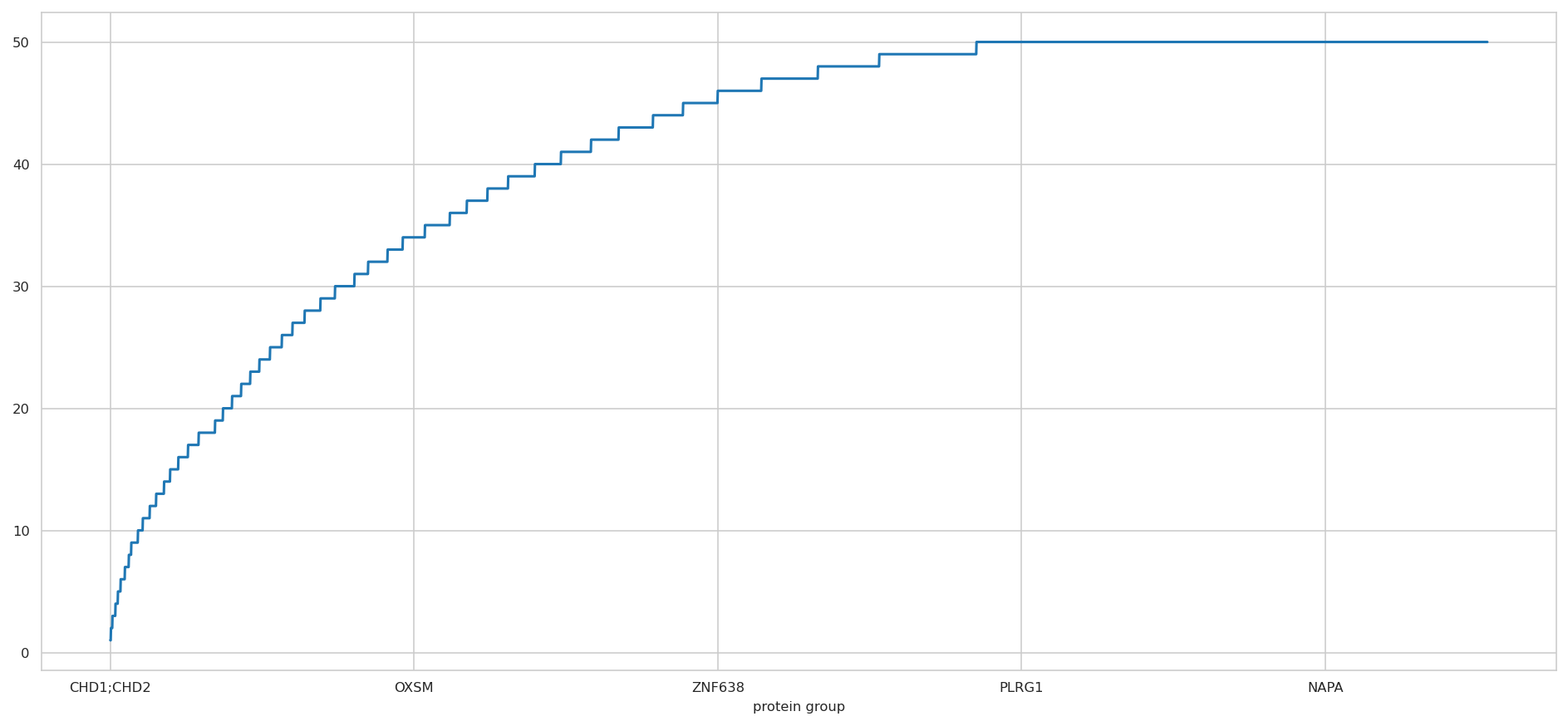
two plots inspecting data availability#
proportion of missing values per feature median (N = protein groups)
CDF of available intensities per protein group
/home/docs/checkouts/readthedocs.org/user_builds/pimms/envs/stable/lib/python3.10/site-packages/pimmslearn/plotting/data.py:323: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
ax = ax[0] # returned series due to by argument?
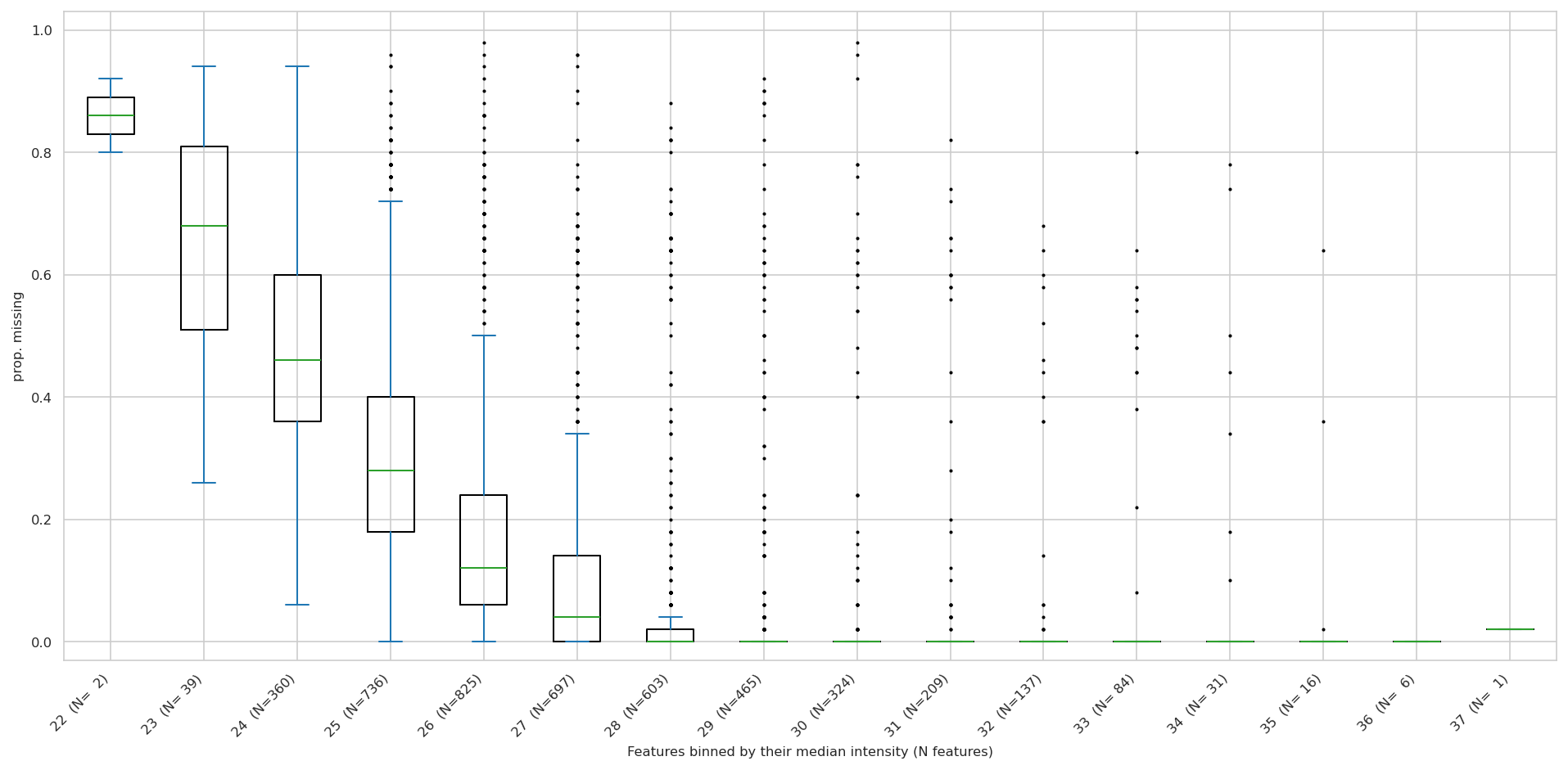
<Axes: xlabel='protein group'>
Data selection#
define a minimum feature and sample frequency for a feature to be included
pimmslearn.filter - INFO Drop 91 along axis 0 (index).
pimmslearn.filter - INFO Drop 0 along axis 1 (columns).
(50, 4444)
Transform to long-data format:
| intensity | ||
|---|---|---|
| Sample ID | protein group | |
| 2019_12_18_14_35_Q-Exactive-HF-X-Orbitrap_6070 | AAAS | 28.349 |
| AACS | 26.133 | |
| AAMP | 26.777 | |
| AAR2 | 27.248 | |
| AARS | 32.195 | |
| ... | ... | ... |
| 2020_06_02_09_41_Q-Exactive-HF-X-Orbitrap_6070 | ZRANB2 | 28.098 |
| ZW10 | 29.425 | |
| ZWINT | 24.794 | |
| ZYX | 29.847 | |
| hCG_2014768;TMA7 | 29.212 |
186965 rows × 1 columns
Optionally: Sample data#
models can be trained without subsetting the data
allows evaluation of the models
/home/docs/checkouts/readthedocs.org/user_builds/pimms/envs/stable/lib/python3.10/site-packages/pimmslearn/sampling.py:208: FutureWarning: Calling float on a single element Series is deprecated and will raise a TypeError in the future. Use float(ser.iloc[0]) instead
loc=float(quantile_frac),
/home/docs/checkouts/readthedocs.org/user_builds/pimms/envs/stable/lib/python3.10/site-packages/pimmslearn/sampling.py:209: FutureWarning: Calling float on a single element Series is deprecated and will raise a TypeError in the future. Use float(ser.iloc[0]) instead
scale=float(0.3 * df_long.std()),
pimmslearn.sampling - INFO int(N * frac_non_train) = 18,696
pimmslearn.sampling - INFO len(fake_na_mnar) = 0
pimmslearn.sampling - INFO len(splits.train_X) = 186,965
pimmslearn.sampling - INFO len(fake_na) = 18,696
pimmslearn.sampling - INFO len(fake_na_mcar) = 18,696
The resulting DataFrame with one column has an MulitIndex with the sample and feature identifier.
Collaborative Filtering#
Inspect annotations of the scikit-learn like Transformer:
# # CollaborativeFilteringTransformer?
Let’s set up collaborative filtering without a validation or test set, using all the data there is.
cf_model = CollaborativeFilteringTransformer(
target_column='intensity',
sample_column='Sample ID',
item_column='protein group',
out_folder='runs/scikit_interface')
We use fit and transform to train the model and impute the missing values.
Scikit learns interface requires a
Xandy.yis the validation data in our context. We might have to change the interface to allow usage within pipelines (->yis not needed). This will probably mean setting up a validation set within the model.
cf_model.fit(splits.train_X,
splits.val_y,
cuda=False,
epochs_max=20,
)
suggested_lr.valley = 0.00363
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 8.605499 | 8.513333 | 00:00 |
| 1 | 8.194693 | 7.402938 | 00:00 |
| 2 | 6.389441 | 3.216072 | 00:00 |
| 3 | 3.608493 | 1.098414 | 00:00 |
| 4 | 2.071536 | 0.877558 | 00:00 |
| 5 | 1.363087 | 0.817680 | 00:00 |
| 6 | 1.019089 | 0.756811 | 00:00 |
| 7 | 0.820775 | 0.642109 | 00:00 |
| 8 | 0.666936 | 0.561466 | 00:00 |
| 9 | 0.571571 | 0.532162 | 00:00 |
| 10 | 0.517684 | 0.516387 | 00:00 |
| 11 | 0.485063 | 0.508955 | 00:00 |
| 12 | 0.463839 | 0.500615 | 00:00 |
| 13 | 0.444313 | 0.495263 | 00:00 |
| 14 | 0.430956 | 0.490960 | 00:00 |
| 15 | 0.422967 | 0.488259 | 00:00 |
| 16 | 0.419574 | 0.487191 | 00:00 |
| 17 | 0.414767 | 0.486214 | 00:00 |
| 18 | 0.410198 | 0.485784 | 00:00 |
| 19 | 0.412085 | 0.485693 | 00:00 |
CollaborativeFilteringTransformer(item_column='protein group',
out_folder=Path('runs/scikit_interface'),
sample_column='Sample ID',
target_column='intensity')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
CollaborativeFilteringTransformer(item_column='protein group',
out_folder=Path('runs/scikit_interface'),
sample_column='Sample ID',
target_column='intensity')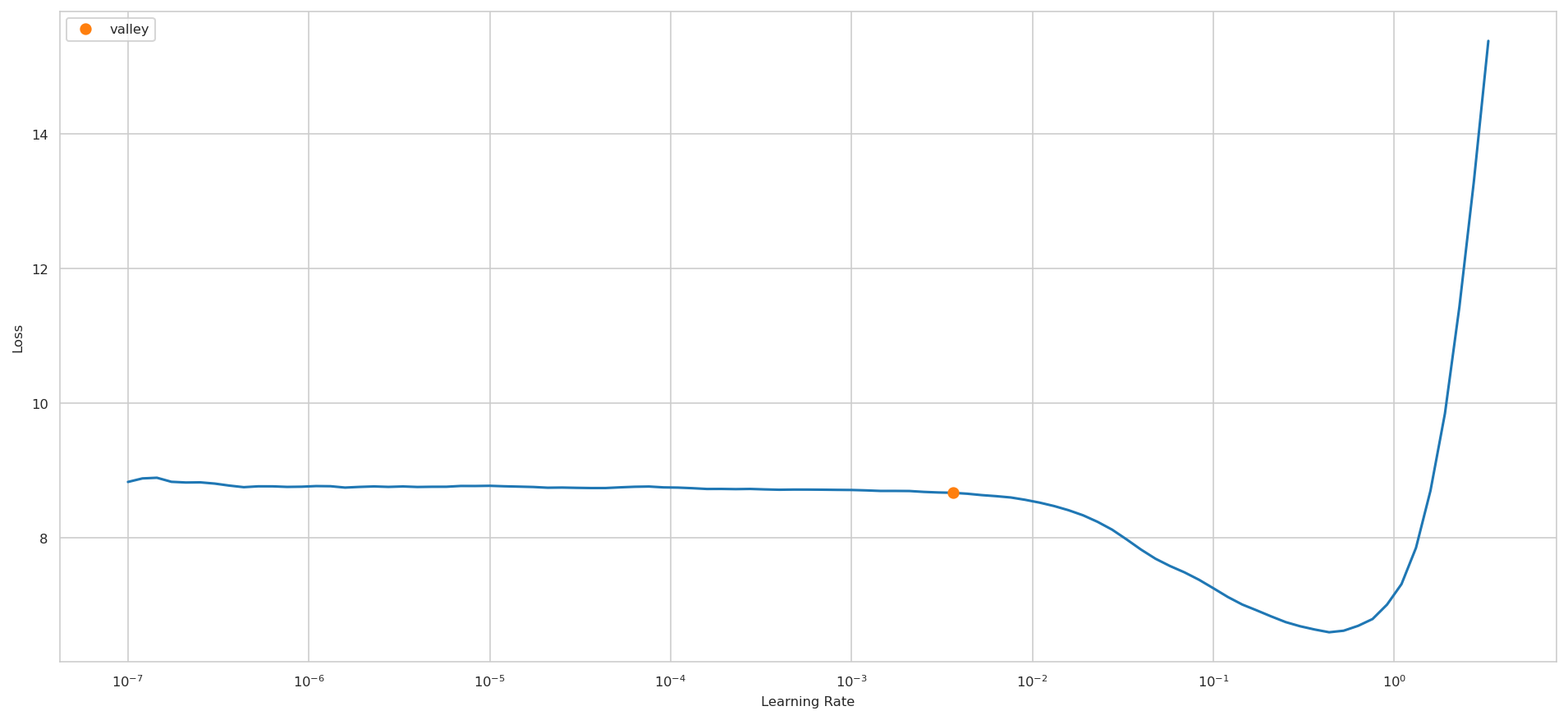
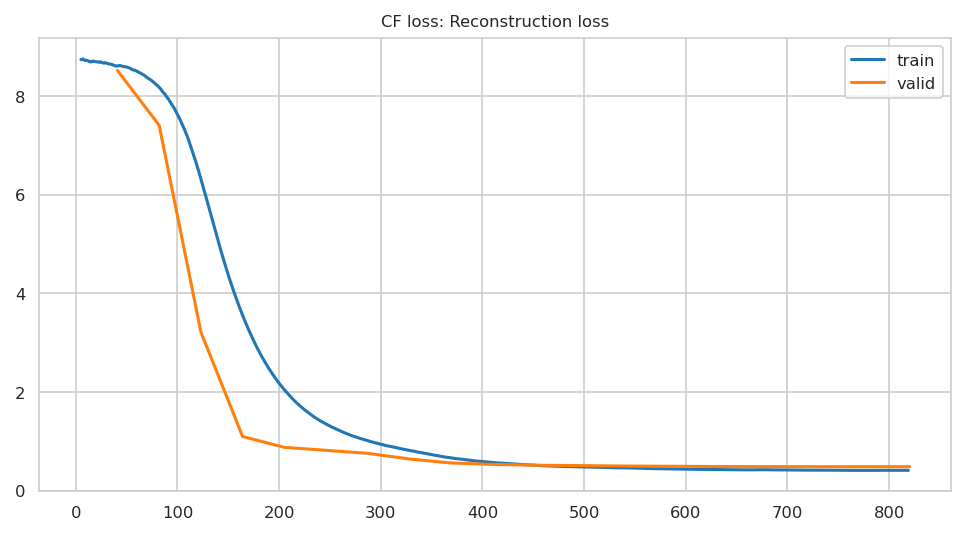
Impute missing values usin transform method:
df_imputed = cf_model.transform(df).unstack()
assert df_imputed.isna().sum().sum() == 0
df_imputed.head()
| protein group | AAAS | AACS | AAMDC | AAMP | AAR2 | AARS | AARS2 | AASDHPPT | AATF | ABCB10 | ... | ZNHIT2 | ZNRF2 | ZPR1 | ZRANB2 | ZW10 | ZWILCH | ZWINT | ZYX | hCG_2014768;TMA7 | pk;ZAK |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| 2019_12_18_14_35_Q-Exactive-HF-X-Orbitrap_6070 | 28.349 | 26.133 | 24.725 | 26.777 | 27.248 | 32.195 | 27.153 | 27.872 | 28.603 | 26.110 | ... | 25.581 | 24.468 | 28.309 | 28.831 | 28.851 | 23.728 | 24.379 | 29.427 | 28.080 | 22.879 |
| 2019_12_19_19_48_Q-Exactive-HF-X-Orbitrap_6070 | 27.657 | 25.019 | 24.236 | 26.271 | 27.211 | 31.979 | 26.530 | 28.191 | 27.942 | 25.735 | ... | 25.093 | 23.925 | 28.133 | 27.267 | 28.243 | 23.294 | 25.497 | 28.081 | 27.642 | 23.624 |
| 2019_12_20_14_15_Q-Exactive-HF-X-Orbitrap_6070 | 28.352 | 23.740 | 24.991 | 27.098 | 27.377 | 32.885 | 27.515 | 28.476 | 28.771 | 26.787 | ... | 25.184 | 24.660 | 28.968 | 27.322 | 29.388 | 23.976 | 25.803 | 29.525 | 28.394 | 24.286 |
| 2019_12_27_12_29_Q-Exactive-HF-X-Orbitrap_6070 | 26.826 | 25.028 | 24.124 | 26.256 | 26.104 | 31.926 | 26.157 | 27.635 | 27.851 | 25.346 | ... | 24.960 | 23.586 | 27.636 | 27.278 | 28.076 | 23.133 | 24.688 | 28.783 | 27.511 | 23.495 |
| 2019_12_29_15_06_Q-Exactive-HF-X-Orbitrap_6070 | 27.404 | 26.948 | 23.864 | 26.982 | 26.520 | 31.844 | 25.342 | 27.416 | 27.474 | 26.308 | ... | 24.591 | 25.621 | 25.838 | 29.326 | 27.491 | 26.406 | 25.306 | 30.422 | 30.422 | 26.939 |
5 rows × 4444 columns
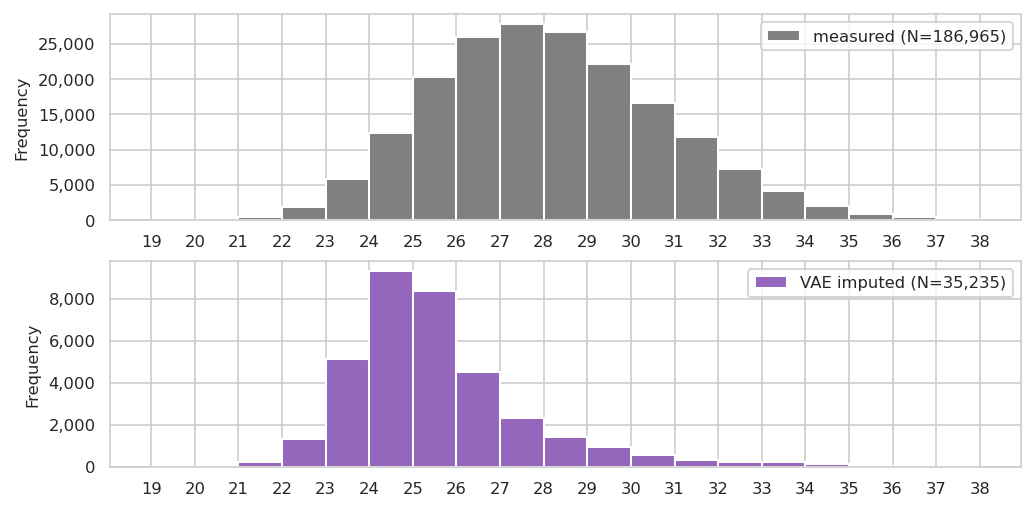
Let’s plot the distribution of the imputed values vs the ones used for training:
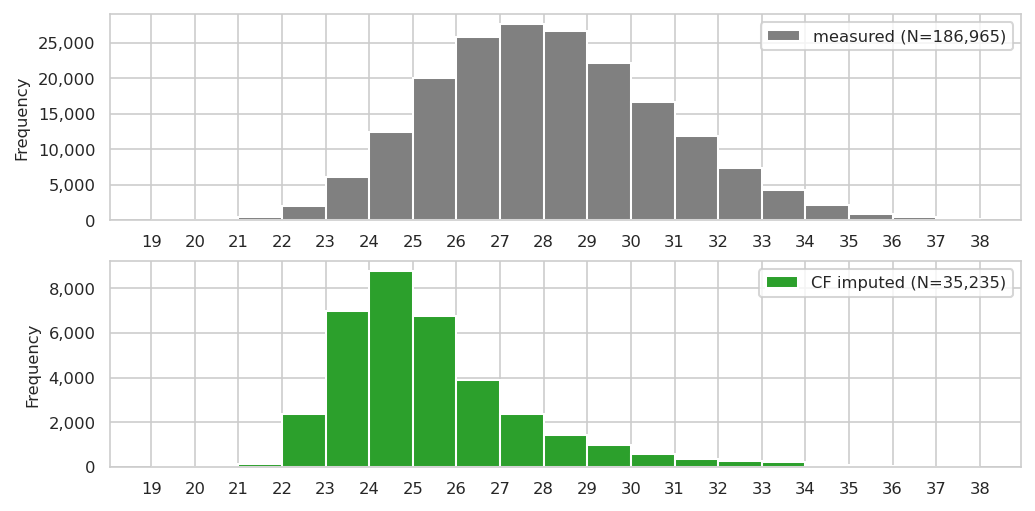
AutoEncoder architectures#
| protein group | AAAS | AACS | AAMDC | AAMP | AAR2 | AARS | AARS2 | AASDHPPT | AATF | ABCB10 | ... | ZNHIT2 | ZNRF2 | ZPR1 | ZRANB2 | ZW10 | ZWILCH | ZWINT | ZYX | hCG_2014768;TMA7 | pk;ZAK |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| 2019_12_18_14_35_Q-Exactive-HF-X-Orbitrap_6070 | 28.349 | 26.133 | NaN | 26.777 | 27.248 | 32.195 | 27.153 | NaN | 28.603 | 26.110 | ... | 25.581 | 24.468 | 28.309 | 28.831 | 28.851 | NaN | 24.379 | 29.427 | 28.080 | 22.879 |
| 2019_12_19_19_48_Q-Exactive-HF-X-Orbitrap_6070 | NaN | 25.019 | 24.236 | 26.271 | 27.211 | 31.979 | 26.530 | 28.191 | 27.942 | 25.735 | ... | NaN | NaN | NaN | 27.267 | 28.243 | NaN | NaN | 28.081 | NaN | NaN |
| 2019_12_20_14_15_Q-Exactive-HF-X-Orbitrap_6070 | 28.352 | 23.740 | NaN | 27.098 | 27.377 | NaN | 27.515 | 28.476 | 28.771 | 26.787 | ... | 25.184 | NaN | 28.968 | 27.322 | 29.388 | NaN | 25.803 | 29.525 | NaN | NaN |
| 2019_12_27_12_29_Q-Exactive-HF-X-Orbitrap_6070 | 26.826 | NaN | NaN | 26.256 | NaN | 31.926 | 26.157 | 27.635 | 27.851 | 25.346 | ... | NaN | 23.586 | 27.636 | 27.278 | 28.076 | NaN | 24.688 | 28.783 | NaN | NaN |
| 2019_12_29_15_06_Q-Exactive-HF-X-Orbitrap_6070 | 27.404 | 26.948 | 23.864 | 26.982 | 26.520 | 31.844 | 25.342 | NaN | 27.474 | NaN | ... | 24.591 | NaN | 25.838 | 29.326 | 27.491 | NaN | NaN | 30.422 | NaN | 26.939 |
| 2019_12_29_18_18_Q-Exactive-HF-X-Orbitrap_6070 | 27.891 | 26.481 | 26.348 | 27.849 | 26.917 | 32.274 | NaN | 27.404 | 28.081 | NaN | ... | 24.849 | NaN | 26.750 | 29.652 | 27.635 | 26.037 | 25.002 | 30.928 | NaN | 27.088 |
| 2020_01_02_17_38_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | 30.226 | NaN | 23.801 | 25.130 | NaN | ... | NaN | NaN | NaN | 27.518 | 25.148 | NaN | NaN | 28.465 | 28.902 | NaN |
| 2020_01_03_11_17_Q-Exactive-HF-X-Orbitrap_6070 | 27.352 | NaN | 24.433 | 25.275 | NaN | 30.979 | NaN | 24.893 | 25.324 | NaN | ... | NaN | NaN | 24.336 | 27.579 | 26.528 | NaN | NaN | 29.726 | 28.933 | NaN |
| 2020_01_03_16_58_Q-Exactive-HF-X-Orbitrap_6070 | 27.620 | 25.624 | 23.520 | 27.136 | 25.971 | 31.415 | 25.360 | 25.119 | 25.750 | NaN | ... | NaN | NaN | 25.198 | 29.245 | 27.331 | 25.069 | NaN | NaN | NaN | 27.086 |
| 2020_01_03_20_10_Q-Exactive-HF-X-Orbitrap_6070 | 27.300 | NaN | 25.660 | 27.733 | 26.897 | NaN | 25.437 | 26.813 | 26.201 | NaN | ... | 24.685 | 24.661 | 25.071 | 28.636 | 26.542 | 24.685 | 24.663 | 31.005 | NaN | 27.081 |
| 2020_01_04_04_23_Q-Exactive-HF-X-Orbitrap_6070 | 27.594 | 27.612 | 26.211 | 27.912 | 27.828 | 32.207 | 26.207 | 27.276 | NaN | NaN | ... | 25.052 | NaN | 26.646 | 29.886 | 28.079 | 24.789 | 25.821 | 31.040 | NaN | 27.296 |
| 2020_01_04_10_03_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | 23.081 | 25.780 | NaN | 30.259 | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | 25.360 | NaN | NaN | NaN | 27.829 | 29.235 | NaN |
| 2020_01_04_14_59_Q-Exactive-HF-X-Orbitrap_6070 | 24.616 | NaN | NaN | 24.765 | NaN | 29.998 | NaN | 24.174 | NaN | NaN | ... | NaN | NaN | 25.253 | 28.000 | 24.597 | NaN | NaN | 29.215 | 29.202 | NaN |
| 2020_01_06_20_17_Q-Exactive-HF-X-Orbitrap_6070 | 28.265 | 27.735 | 27.055 | 28.733 | 28.167 | 32.554 | 25.292 | NaN | 26.711 | NaN | ... | NaN | NaN | NaN | 28.904 | NaN | 25.628 | NaN | 31.364 | NaN | 28.089 |
| 2020_01_08_16_43_Q-Exactive-HF-X-Orbitrap_6070 | 25.734 | 25.442 | NaN | 25.347 | 25.573 | 31.127 | NaN | 24.365 | NaN | NaN | ... | NaN | NaN | NaN | 28.213 | 27.034 | NaN | NaN | 29.550 | NaN | 26.038 |
| 2020_01_09_11_07_Q-Exactive-HF-X-Orbitrap_6070 | 26.167 | NaN | NaN | 26.877 | 25.986 | 31.450 | 23.883 | 25.810 | 26.233 | NaN | ... | NaN | NaN | NaN | 29.214 | 27.125 | NaN | 24.593 | 30.142 | 29.919 | NaN |
| 2020_01_15_13_56_Q-Exactive-HF-X-Orbitrap_6070 | 26.019 | 23.935 | NaN | 24.982 | NaN | 31.423 | 25.218 | 27.088 | 27.190 | 24.796 | ... | NaN | NaN | 27.588 | 27.579 | 27.236 | NaN | 24.458 | 28.274 | NaN | NaN |
| 2020_01_20_15_10_Q-Exactive-HF-X-Orbitrap_6070 | NaN | 25.257 | NaN | NaN | 28.211 | 32.706 | 26.536 | 28.103 | 28.168 | NaN | ... | NaN | NaN | 27.765 | 30.309 | 29.199 | NaN | 26.088 | 31.172 | NaN | 28.287 |
| 2020_02_05_20_55_Q-Exactive-HF-X-Orbitrap_6070 | 28.157 | 27.489 | NaN | 28.594 | 27.077 | 32.383 | 26.182 | NaN | 27.834 | NaN | ... | 24.657 | 27.386 | 25.160 | NaN | 28.630 | 25.718 | NaN | 31.277 | NaN | 28.386 |
| 2020_02_10_15_41_Q-Exactive-HF-X-Orbitrap_6070 | 29.216 | NaN | 25.797 | NaN | 28.929 | 33.656 | 27.984 | 29.301 | 30.141 | NaN | ... | 26.945 | NaN | 30.179 | 29.450 | 29.721 | NaN | 26.972 | 30.912 | 28.756 | NaN |
| 2020_02_11_10_35_Q-Exactive-HF-X-Orbitrap_6070 | 29.156 | 27.582 | 25.516 | 27.251 | NaN | NaN | 27.977 | NaN | 29.880 | 27.348 | ... | 27.031 | NaN | 29.081 | NaN | 29.949 | 25.797 | 31.137 | 30.381 | NaN | NaN |
| 2020_02_12_05_06_Q-Exactive-HF-X-Orbitrap_6070 | 29.255 | 27.394 | 26.058 | 27.348 | 28.755 | 33.793 | 29.140 | 28.825 | 30.001 | 28.209 | ... | NaN | NaN | 29.925 | 29.958 | 30.142 | 25.309 | 27.381 | 30.655 | NaN | NaN |
| 2020_02_13_00_26_Q-Exactive-HF-X-Orbitrap_6070 | 29.606 | 27.286 | 26.377 | 26.431 | 27.898 | 33.962 | NaN | 29.481 | 30.180 | 27.825 | ... | 26.946 | 26.276 | 30.236 | 29.713 | 29.636 | 26.038 | 27.857 | 30.738 | NaN | NaN |
| 2020_02_13_03_11_Q-Exactive-HF-X-Orbitrap_6070 | 27.712 | 26.283 | NaN | 26.762 | 28.006 | 33.848 | 28.954 | 29.958 | 29.293 | NaN | ... | 26.706 | 26.542 | NaN | 29.757 | 29.471 | 25.575 | 27.986 | 30.951 | NaN | NaN |
| 2020_02_17_13_55_Q-Exactive-HF-X-Orbitrap_6070 | 28.435 | 26.624 | 25.520 | 26.746 | 26.224 | 32.584 | 28.020 | 27.786 | 28.410 | 26.512 | ... | 26.425 | NaN | 29.144 | 29.086 | 28.943 | 24.317 | 25.066 | 29.478 | NaN | NaN |
| 2020_02_18_01_25_Q-Exactive-HF-X-Orbitrap_6070 | 26.691 | 25.331 | NaN | 25.831 | 23.969 | 32.741 | 26.967 | 28.236 | 28.260 | 27.266 | ... | 24.340 | 24.216 | 29.082 | 28.328 | 28.738 | 23.202 | 26.282 | 29.733 | NaN | 22.075 |
| 2020_02_18_18_55_Q-Exactive-HF-X-Orbitrap_6070 | NaN | 24.772 | 23.877 | 26.146 | 27.353 | 32.433 | 27.537 | 28.055 | 28.535 | 27.914 | ... | NaN | 24.773 | 28.231 | 27.755 | 28.956 | 24.298 | 25.263 | 29.180 | NaN | NaN |
| 2020_02_28_12_27_Q-Exactive-HF-X-Orbitrap_6070 | 27.702 | 25.953 | 24.649 | 26.582 | 27.248 | NaN | 26.985 | 27.615 | 27.874 | 26.436 | ... | NaN | NaN | 28.108 | NaN | 28.125 | 23.248 | 23.587 | 29.475 | NaN | NaN |
| 2020_03_01_23_00_Q-Exactive-HF-X-Orbitrap_6070 | 27.596 | 25.257 | 22.921 | 24.869 | 26.878 | 32.064 | 26.496 | 26.617 | 27.837 | 25.854 | ... | 23.869 | NaN | 28.118 | 27.876 | 27.828 | NaN | 24.423 | 28.864 | NaN | NaN |
| 2020_03_06_16_22_Q-Exactive-HF-X-Orbitrap_6070 | 26.089 | 23.806 | 22.751 | 25.799 | 24.384 | 30.550 | NaN | 24.911 | 25.216 | NaN | ... | NaN | NaN | 24.773 | 27.669 | 25.882 | NaN | NaN | 28.426 | NaN | 25.356 |
| 2020_03_07_18_15_Q-Exactive-HF-X-Orbitrap_6070 | 26.891 | 24.577 | 25.052 | 26.740 | 26.882 | NaN | NaN | 25.916 | 24.219 | NaN | ... | 24.296 | NaN | 26.138 | 28.962 | 26.890 | 25.057 | NaN | 29.190 | NaN | 26.855 |
| 2020_03_11_11_25_Q-Exactive-HF-X-Orbitrap_6070 | 27.699 | 26.344 | NaN | 25.791 | 27.523 | NaN | 27.716 | 28.179 | 28.601 | 27.517 | ... | 26.404 | 23.770 | NaN | 28.115 | 28.806 | 24.492 | 25.244 | 29.521 | NaN | NaN |
| 2020_05_04_11_39_Q-Exactive-HF-X-Orbitrap_6070 | NaN | 25.320 | NaN | 25.801 | 25.236 | 31.472 | 26.096 | 27.627 | 26.755 | 24.640 | ... | 25.051 | NaN | 27.260 | 28.086 | 27.064 | NaN | NaN | 28.430 | NaN | NaN |
| 2020_05_12_15_13_Q-Exactive-HF-X-Orbitrap_6070 | 27.138 | 25.875 | NaN | 25.722 | 26.513 | 31.377 | 26.142 | 27.486 | 27.267 | 26.009 | ... | 24.935 | NaN | 27.425 | NaN | 27.718 | 22.851 | 24.988 | 28.414 | 27.406 | NaN |
| 2020_05_12_18_10_Q-Exactive-HF-X-Orbitrap_6070 | 26.844 | 24.719 | 25.460 | 25.282 | 25.656 | 30.942 | 26.304 | 26.419 | 26.825 | NaN | ... | NaN | NaN | 27.222 | NaN | 27.165 | NaN | 22.620 | 27.841 | 26.861 | NaN |
| 2020_05_12_21_07_Q-Exactive-HF-X-Orbitrap_6070 | 26.853 | 25.421 | NaN | NaN | 25.596 | NaN | 26.026 | 26.243 | 27.130 | 25.424 | ... | 24.957 | NaN | 26.966 | 27.552 | NaN | 22.819 | 24.906 | 28.062 | 26.830 | NaN |
| 2020_05_14_14_46_Q-Exactive-HF-X-Orbitrap_6070 | 26.203 | NaN | 23.161 | 24.822 | 26.838 | 31.714 | 26.388 | 26.211 | 26.895 | 24.676 | ... | NaN | NaN | 27.176 | 27.620 | 27.762 | 23.260 | 28.917 | 28.554 | NaN | NaN |
| 2020_05_14_17_28_Q-Exactive-HF-X-Orbitrap_6070 | 27.203 | 23.885 | 23.234 | 25.293 | 26.415 | NaN | 26.677 | 26.635 | NaN | 25.155 | ... | 25.425 | 24.426 | 27.383 | 27.327 | 27.766 | 22.375 | 29.057 | 28.312 | NaN | NaN |
| 2020_05_14_20_11_Q-Exactive-HF-X-Orbitrap_6070 | NaN | 25.154 | 23.142 | 25.126 | 26.066 | 31.983 | 26.534 | 27.689 | 27.233 | 25.296 | ... | 25.439 | NaN | 27.429 | 28.054 | 27.582 | NaN | 25.244 | 28.480 | 27.948 | NaN |
| 2020_05_15_10_30_Q-Exactive-HF-X-Orbitrap_6070 | 27.494 | 25.606 | 25.852 | 25.617 | 24.857 | 32.562 | 27.693 | 28.119 | 28.009 | 25.884 | ... | 25.679 | NaN | 27.664 | 28.274 | 28.464 | 22.570 | 26.519 | 29.356 | NaN | NaN |
| 2020_05_20_12_33_Q-Exactive-HF-X-Orbitrap_6070 | NaN | 25.552 | NaN | 25.741 | 25.893 | 31.680 | 25.822 | 27.158 | NaN | 25.629 | ... | 25.054 | 24.491 | 28.688 | 25.496 | 27.340 | NaN | 25.492 | 28.276 | 28.252 | NaN |
| 2020_05_20_15_35_Q-Exactive-HF-X-Orbitrap_6070 | 27.721 | 24.916 | 24.125 | 26.078 | 26.726 | 32.368 | 27.015 | 27.807 | 27.217 | NaN | ... | 25.176 | 23.532 | 28.525 | 28.459 | 27.581 | NaN | 26.087 | 28.691 | NaN | NaN |
| 2020_05_22_14_57_Q-Exactive-HF-X-Orbitrap_6070 | 27.808 | 24.714 | NaN | 25.857 | 25.693 | 32.394 | 27.619 | 27.153 | NaN | 25.988 | ... | 25.142 | NaN | NaN | 27.482 | 27.941 | NaN | NaN | 28.632 | 26.564 | NaN |
| 2020_05_22_17_43_Q-Exactive-HF-X-Orbitrap_6070 | 28.051 | 25.608 | 26.030 | 26.375 | 25.536 | NaN | 27.501 | 28.506 | 27.846 | 25.779 | ... | NaN | 23.442 | 28.081 | 28.437 | 28.081 | 22.678 | NaN | 28.992 | NaN | NaN |
| 2020_05_26_14_20_Q-Exactive-HF-X-Orbitrap_6070 | 27.325 | 26.800 | 25.519 | 25.204 | 27.263 | 33.171 | 28.125 | 28.389 | 28.409 | 27.050 | ... | NaN | 25.162 | 29.071 | 28.690 | 28.289 | 23.853 | NaN | 29.962 | NaN | NaN |
| 2020_05_27_13_57_Q-Exactive-HF-X-Orbitrap_6070 | NaN | 27.061 | 25.989 | 27.999 | 28.294 | 34.448 | NaN | 30.015 | 29.825 | 28.311 | ... | 26.922 | 25.578 | 30.025 | 29.927 | NaN | 24.652 | 27.951 | 30.794 | NaN | NaN |
| 2020_05_28_04_06_Q-Exactive-HF-X-Orbitrap_6070 | 30.080 | 27.373 | 26.760 | 27.601 | 28.023 | NaN | 28.785 | 30.316 | 29.114 | 29.002 | ... | 26.960 | NaN | 30.156 | 29.833 | 30.456 | 26.042 | NaN | 31.340 | NaN | NaN |
| 2020_06_01_10_22_Q-Exactive-HF-X-Orbitrap_6070 | 27.298 | NaN | 23.002 | 28.318 | NaN | 31.398 | 23.917 | NaN | 26.357 | NaN | ... | 25.702 | NaN | 23.989 | 27.854 | 27.574 | NaN | NaN | 29.383 | 29.336 | 25.825 |
| 2020_06_01_15_41_Q-Exactive-HF-X-Orbitrap_6070 | 27.121 | NaN | NaN | 27.968 | 26.707 | 31.958 | NaN | 26.219 | NaN | NaN | ... | 26.590 | NaN | 26.180 | 27.946 | 28.721 | 25.082 | NaN | 30.147 | 29.707 | NaN |
| 2020_06_02_09_41_Q-Exactive-HF-X-Orbitrap_6070 | NaN | 25.989 | 25.120 | 26.944 | NaN | 33.220 | 27.455 | 28.759 | NaN | 27.160 | ... | 26.946 | NaN | NaN | 28.098 | 29.425 | NaN | NaN | 29.847 | 29.212 | NaN |
50 rows × 4444 columns
Validation data for early stopping (if specified)
| protein group | STK4 | CDK7 | GNA11 | MBNL1 | HEXB | ACTR5 | DYNLL2 | CDC2;CDK1 | TXNL4A | ITGA3 | ... | TANC1 | MRPL21 | BDH2 | DCTD | TIMM22 | PRPSAP2 | GCHFR | MFN2 | LAMTOR2 | SEL1L |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sample ID | |||||||||||||||||||||
| 2019_12_18_14_35_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | 26.996 | NaN | NaN | NaN |
| 2019_12_19_19_48_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | 26.857 | NaN | NaN | NaN | NaN |
| 2019_12_20_14_15_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2019_12_27_12_29_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | 28.401 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2019_12_29_15_06_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2019_12_29_18_18_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_02_17_38_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_03_11_17_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_03_16_58_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 26.939 | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_03_20_10_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_04_04_23_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | 29.219 | NaN | NaN | NaN | 27.446 | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_04_10_03_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_04_14_59_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 29.962 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_06_20_17_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | 29.445 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_08_16_43_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_09_11_07_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_15_13_56_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_01_20_15_10_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 29.791 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_02_05_20_55_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | 26.916 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_02_10_15_41_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_02_11_10_35_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | 25.622 | NaN | NaN | NaN | NaN | NaN |
| 2020_02_12_05_06_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | 27.145 | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 26.979 | NaN |
| 2020_02_13_00_26_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | 29.261 | NaN | NaN | NaN | NaN |
| 2020_02_13_03_11_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | 27.963 | NaN | NaN | NaN | NaN | NaN | 30.115 | NaN | 27.568 |
| 2020_02_17_13_55_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_02_18_01_25_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 31.345 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_02_18_18_55_Q-Exactive-HF-X-Orbitrap_6070 | 27.463 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_02_28_12_27_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | 25.191 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_03_01_23_00_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_03_06_16_22_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | 28.024 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_03_07_18_15_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | 28.856 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_03_11_11_25_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | 27.337 | 28.907 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_04_11_39_Q-Exactive-HF-X-Orbitrap_6070 | 24.646 | NaN | NaN | 27.748 | NaN | NaN | 23.521 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_12_15_13_Q-Exactive-HF-X-Orbitrap_6070 | 25.398 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | 22.155 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_12_18_10_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 24.794 | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_12_21_07_Q-Exactive-HF-X-Orbitrap_6070 | 25.139 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_14_14_46_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_14_17_28_Q-Exactive-HF-X-Orbitrap_6070 | NaN | 25.654 | NaN | NaN | 28.554 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_14_20_11_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_15_10_30_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_20_12_33_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_20_15_35_Q-Exactive-HF-X-Orbitrap_6070 | NaN | 24.790 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_22_14_57_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_22_17_43_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 24.003 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_26_14_20_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | 26.272 | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_27_13_57_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | 30.326 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_05_28_04_06_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_06_01_10_22_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_06_01_15_41_Q-Exactive-HF-X-Orbitrap_6070 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020_06_02_09_41_Q-Exactive-HF-X-Orbitrap_6070 | 27.082 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
50 rows × 3832 columns
Training and validation need the same shape:
(50, 4444) (50, 4444)
Select either DAE or VAE model by chance:
model_selected = random.choice(['DAE', 'VAE'])
print("Selected model by chance:", model_selected)
model = AETransformer(
model=model_selected,
hidden_layers=[512,],
latent_dim=50,
out_folder='runs/scikit_interface',
batch_size=10,
)
Selected model by chance: VAE
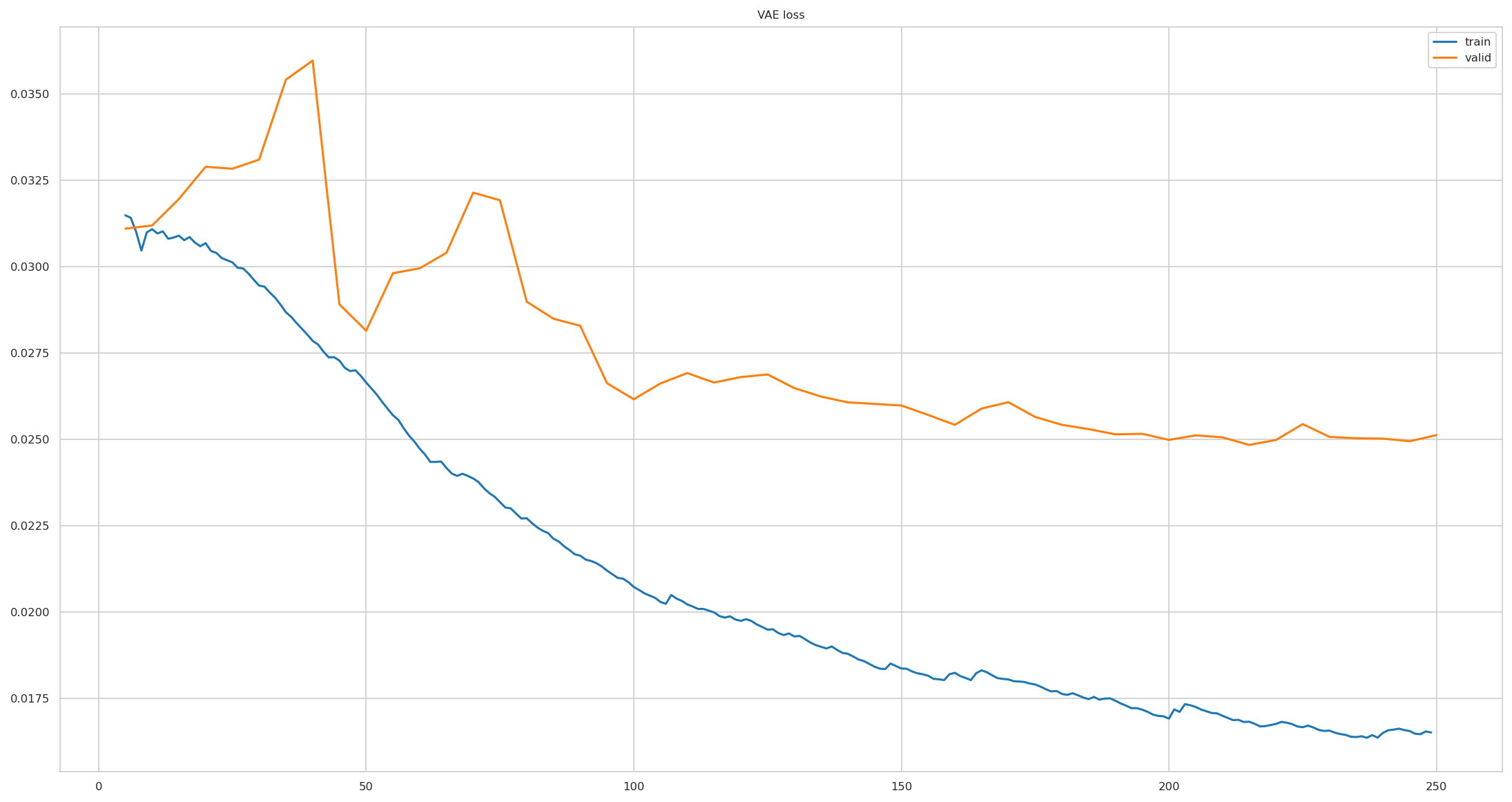
model.fit(splits.train_X, splits.val_y,
epochs_max=50,
cuda=False)
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 5235.916504 | 290.709564 | 00:00 |
| 1 | 5214.595215 | 291.549133 | 00:00 |
| 2 | 5189.329102 | 298.711792 | 00:00 |
| 3 | 5146.856445 | 307.437683 | 00:00 |
| 4 | 5078.784668 | 306.910736 | 00:00 |
| 5 | 4983.731934 | 309.382996 | 00:00 |
| 6 | 4862.459961 | 330.997742 | 00:00 |
| 7 | 4716.803223 | 336.181732 | 00:00 |
| 8 | 4606.648438 | 270.213715 | 00:00 |
| 9 | 4515.353516 | 263.080811 | 00:00 |
| 10 | 4355.652344 | 278.641449 | 00:00 |
| 11 | 4196.036133 | 279.962921 | 00:00 |
| 12 | 4098.586426 | 284.159698 | 00:00 |
| 13 | 4028.290283 | 300.430847 | 00:00 |
| 14 | 3926.989990 | 298.381409 | 00:00 |
| 15 | 3820.937744 | 270.939209 | 00:00 |
| 16 | 3749.780273 | 266.327057 | 00:00 |
| 17 | 3646.341064 | 264.406219 | 00:00 |
| 18 | 3587.672852 | 248.891388 | 00:00 |
| 19 | 3510.950439 | 244.524109 | 00:00 |
| 20 | 3434.216064 | 248.825256 | 00:00 |
| 21 | 3419.445557 | 251.610138 | 00:00 |
| 22 | 3372.009277 | 249.057846 | 00:00 |
| 23 | 3328.837891 | 250.529099 | 00:00 |
| 24 | 3292.486328 | 251.250427 | 00:00 |
| 25 | 3261.096680 | 247.558304 | 00:00 |
| 26 | 3204.275146 | 245.258926 | 00:00 |
| 27 | 3166.374268 | 243.693665 | 00:00 |
| 28 | 3112.714844 | 243.276093 | 00:00 |
| 29 | 3102.219727 | 242.854095 | 00:00 |
| 30 | 3062.324463 | 240.292892 | 00:00 |
| 31 | 3062.538574 | 237.615082 | 00:00 |
| 32 | 3067.758301 | 242.016052 | 00:00 |
| 33 | 3039.737305 | 243.744415 | 00:00 |
| 34 | 3016.947754 | 239.753052 | 00:00 |
| 35 | 2980.817383 | 237.615662 | 00:00 |
| 36 | 2949.188965 | 236.454300 | 00:00 |
| 37 | 2945.035645 | 235.040085 | 00:00 |
| 38 | 2897.262207 | 235.187500 | 00:00 |
| 39 | 2857.411377 | 233.538788 | 00:00 |
| 40 | 2911.201660 | 234.762787 | 00:00 |
| 41 | 2871.668701 | 234.231705 | 00:00 |
| 42 | 2829.766602 | 232.180054 | 00:00 |
| 43 | 2814.951172 | 233.510269 | 00:00 |
| 44 | 2808.023438 | 237.814590 | 00:00 |
| 45 | 2786.197021 | 234.358200 | 00:00 |
| 46 | 2757.927734 | 233.975601 | 00:00 |
| 47 | 2753.590332 | 233.888107 | 00:00 |
| 48 | 2790.276123 | 233.172287 | 00:00 |
| 49 | 2778.630371 | 234.837692 | 00:00 |
pimmslearn.plotting - INFO Saved Figures to runs/scikit_interface/vae_training
AETransformer(batch_size=10, hidden_layers=[512], latent_dim=50,
model=<class 'pimmslearn.models.vae.VAE'>,
out_folder=Path('runs/scikit_interface'))In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
AETransformer(batch_size=10, hidden_layers=[512], latent_dim=50,
model=<class 'pimmslearn.models.vae.VAE'>,
out_folder=Path('runs/scikit_interface'))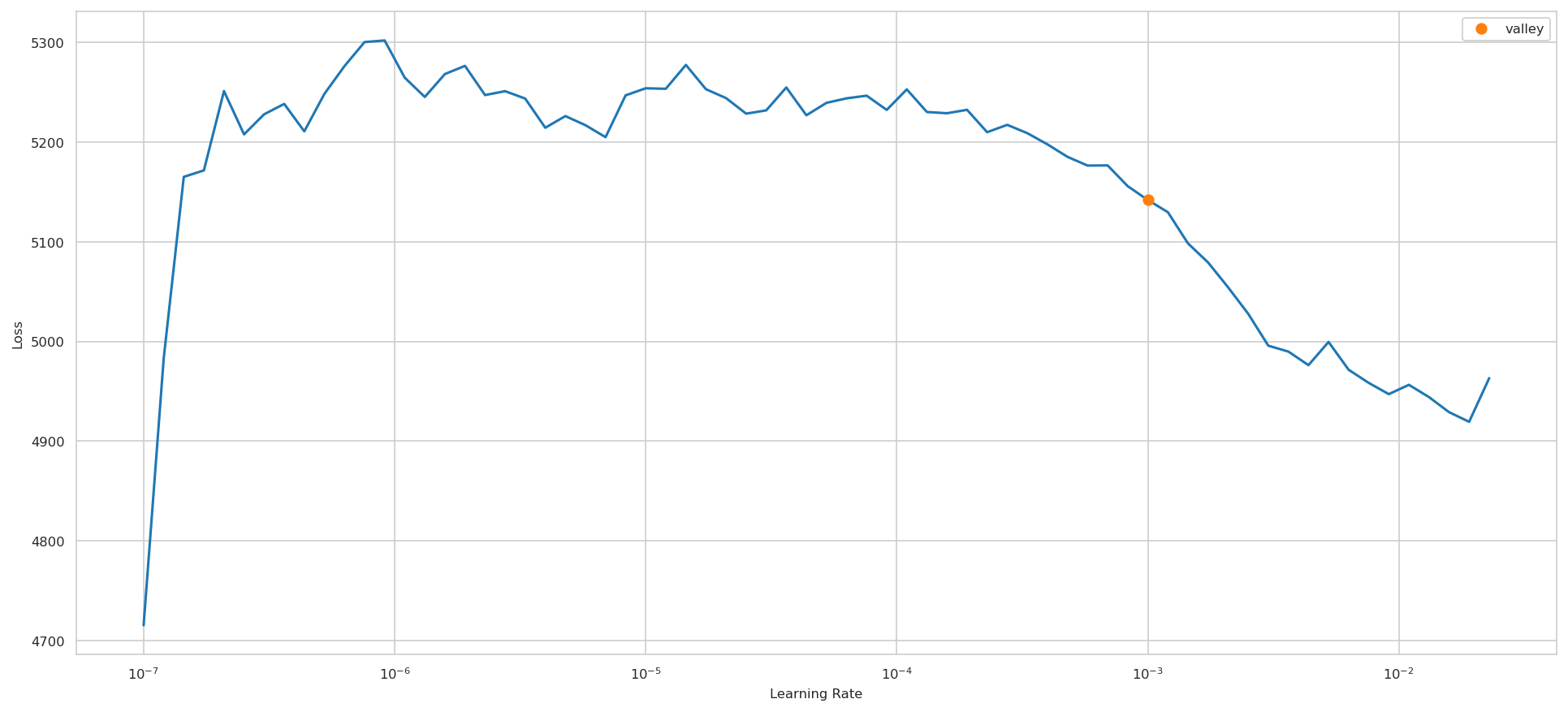
Impute missing values using transform method:
df_imputed = model.transform(splits.train_X).stack()
df_imputed
Sample ID protein group
2019_12_18_14_35_Q-Exactive-HF-X-Orbitrap_6070 AAAS 28.349
AACS 26.133
AAMDC 24.852
AAMP 26.777
AAR2 27.248
...
2020_06_02_09_41_Q-Exactive-HF-X-Orbitrap_6070 ZWILCH 24.547
ZWINT 26.395
ZYX 29.847
hCG_2014768;TMA7 29.212
pk;ZAK 24.568
Length: 222200, dtype: float64
Evaluate the model using the validation data:
{'VAE': {'MSE': 0.5361104967873574,
'MAE': 0.505678843210243,
'N': 9348,
'prop': 1.0}}
/home/docs/checkouts/readthedocs.org/user_builds/pimms/envs/stable/lib/python3.10/site-packages/pimmslearn/plotting/errors.py:105: FutureWarning:
The `errwidth` parameter is deprecated. And will be removed in v0.15.0. Pass `err_kws={'linewidth': 1.2}` instead.
sns.barplot(
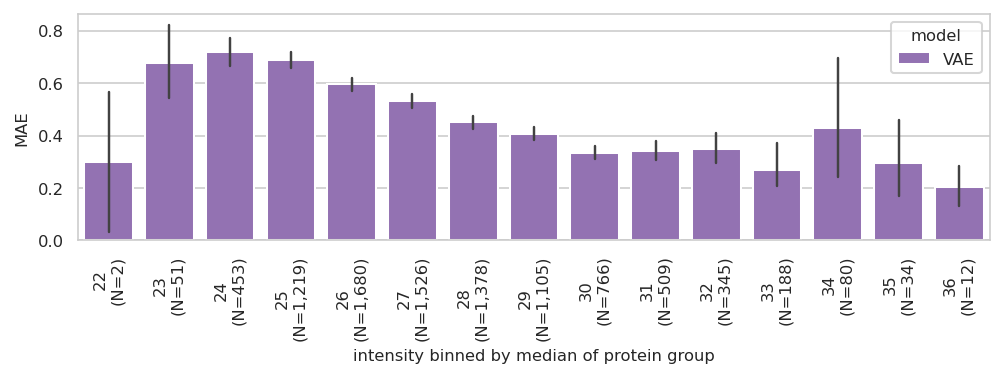
replace predicted values with validation data values
Sample ID protein group
2019_12_18_14_35_Q-Exactive-HF-X-Orbitrap_6070 AAAS 28.349
AACS 26.133
AAMDC 24.852
AAMP 26.777
AAR2 27.248
...
2020_06_02_09_41_Q-Exactive-HF-X-Orbitrap_6070 ZWILCH 24.547
ZWINT 26.395
ZYX 29.847
hCG_2014768;TMA7 29.212
pk;ZAK 24.568
Length: 222200, dtype: float64
Plot the distribution of the imputed values vs the observed data: